D-CLING: Prior-Preserving Depth-Conditioned
Fine-Tuning for Navigation Foundation Models
Frontier Research Center, Toyota Motor Corporation
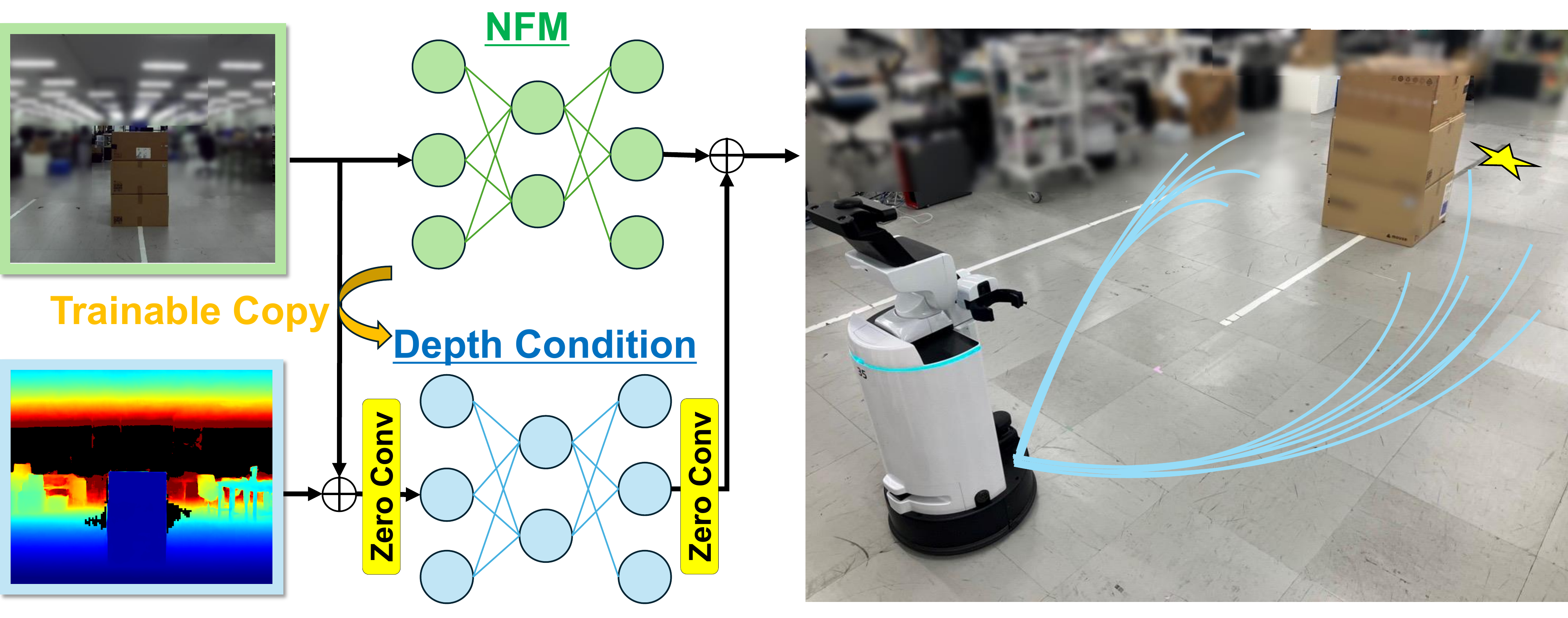
A full overview of the D-CLING framework.
Navigation Foundation Models (NFMs) trained on large, cross-embodied datasets have demonstrated powerful generalizability across various scenarios. Adopting in-domain fine-tuning upon an NFM efficiently calibrates the visuomotor policy, promising further improvement even in novel scenarios. However, fine-tuned models still suffer from poor obstacle avoidance or fail to properly reach provided goals. Furthermore, such model updates on a small subset of data typically erode the pretrained prior, compromising pretraining generalization.
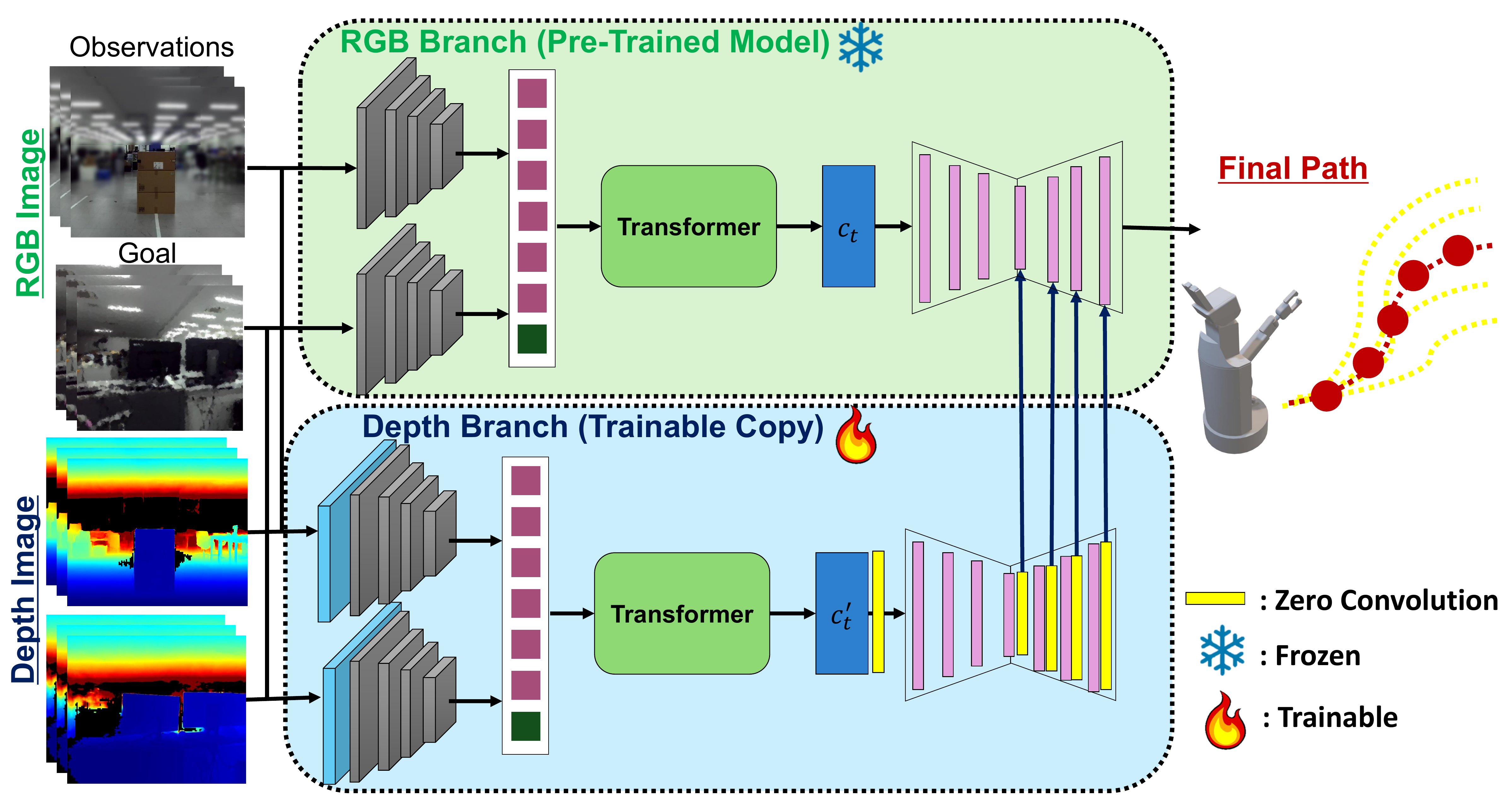
In this work, we present D-CLING (Depth-Conditioned, ControlNet-driven Learning for General Navigation Models), a novel fine-tuning method that leverages large-scale pretraining while efficiently learning in novel setups. Inspired by ControlNet, we fine-tune an NFM by attaching a trainable copy of the pretrained backbone using zero-initialized residual pathways, thereby learning geometric cues from dense depth maps. This design enables the model to efficiently acquire in-domain geometry while preserving pretrained knowledge across various behaviors.
Retains pretrained policy priors while explicitly injecting geometry-awareness through depth conditioning.
Superior goal reachability and obstacle avoidance in both real-robot deployments and offline evaluations.
The fine-tuned model extends navigation capability beyond the fine-tuning domain, enabling continuous learning.
Why do Navigation Foundation Models need depth-conditioned fine-tuning?


ControlNet-inspired prior-preserving architecture: frozen RGB policy + trainable depth branch
Evaluated on Toyota HSR robot across three challenging scenarios
Corridor traversal with visual avoidance of a stationary box.
After 10m travel, avoid an unmapped chair at corridor center.
~50m trajectory across two junctions with scene dynamics.
| Method | Training | Modality | (i) Basic Obstacle SR (%) ↑ |
(ii) Dynamic Corridor SR (%) ↑ |
(iii) Long-range Interventions ↓ |
|---|---|---|---|---|---|
| NoMaD | Frozen | RGB | 50 | 0 | 2.6 |
| NoMaD-FT | Full fine-tune | RGB | 30 | 10 | 3.2 |
| NoMaD-EF | Early fusion | RGB-D | 40 | 0 | 4.4 |
| D-CLING (Ours) | Zero-init | RGB-D | 70 | 60 | 1.2 |
Action prediction accuracy across fine-tuning and pretrained domains
| Method | F.T. Dataset RealHSRNav |
Recon | GoStanford | Sacson | Scand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADE | FDE | DTW | ADE | FDE | DTW | ADE | FDE | DTW | ADE | FDE | DTW | ADE | FDE | DTW | |
| NoMaD | 1.326 | 2.160 | 0.917 | 1.691 | 2.996 | 1.301 | 2.267 | 4.448 | 1.888 | 2.508 | 4.285 | 2.003 | 2.035 | 2.990 | 1.283 |
| NoMaD-FT | 2.138 | 5.484 | 2.255 | 1.810 | 4.775 | 1.956 | 2.097 | 5.436 | 2.216 | 1.861 | 4.435 | 1.913 | 1.622 | 4.115 | 1.659 |
| NoMaD-EF | 1.897 | 4.244 | 1.674 | 2.222 | 4.676 | 1.991 | 2.540 | 6.246 | 2.592 | 2.737 | 5.497 | 2.455 | 2.428 | 5.063 | 2.045 |
| D-CLING (Ours) | 1.298 | 1.443 | 0.726 | 1.502 | 3.037 | 1.312 | 1.812 | 4.275 | 1.739 | 2.521 | 4.385 | 1.929 | 1.839 | 2.401 | 1.065 |
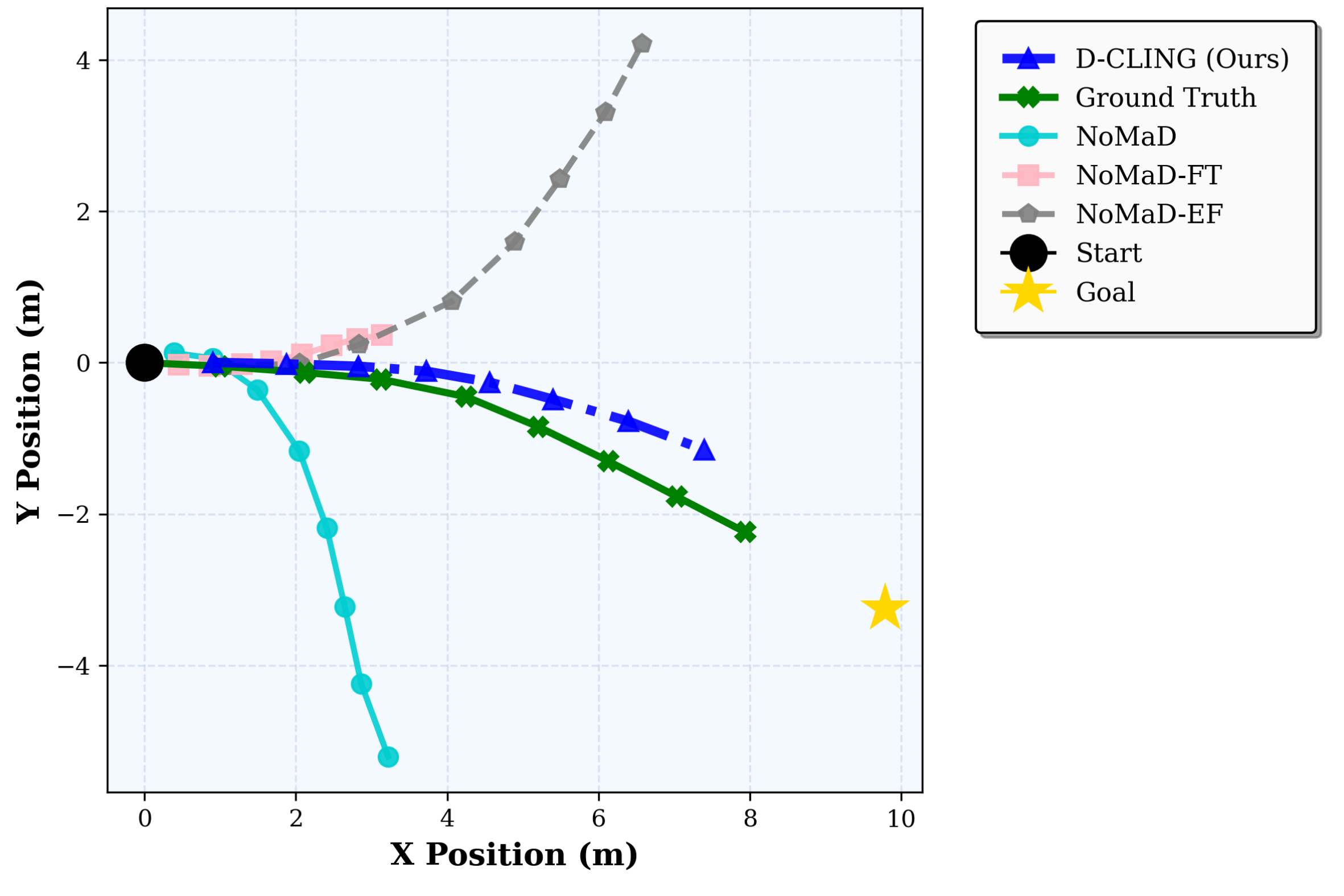
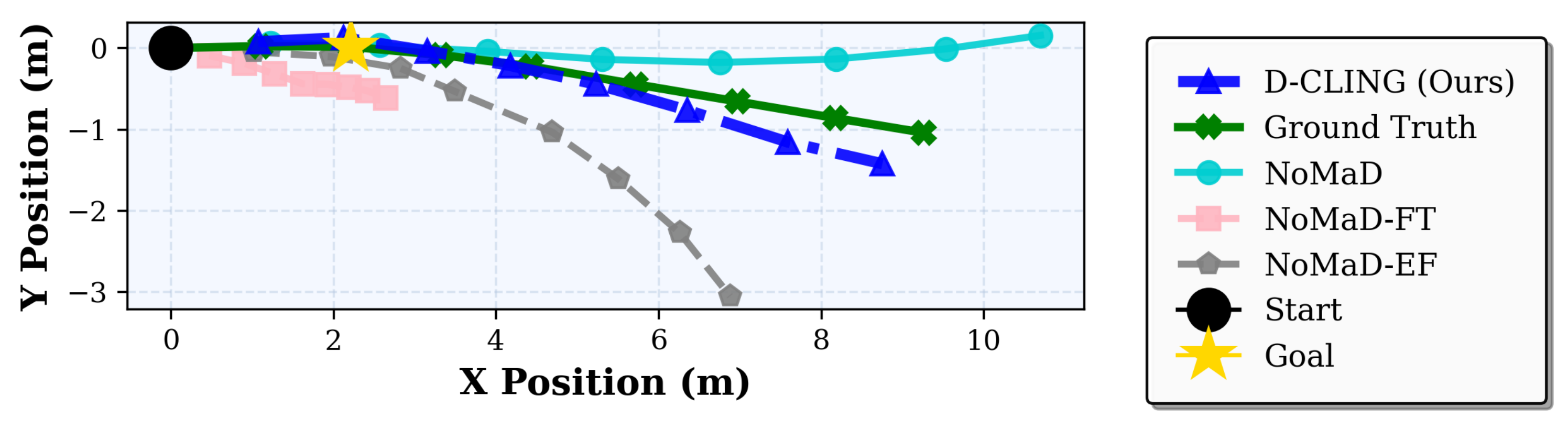
D-CLING fine-tuned only on RealHSRNav achieves competitive or even better performance on the NoMaD pretraining datasets compared to zero-shot NoMaD. This demonstrates that our approach not only adapts to the target domain but also extends the pretrained model's capability, supporting continuous learning for general navigation.
Validating the benefit of depth conditioning in the ControlNet architecture
The robot traverses a corridor while avoiding a single stationary chair placed along its route. This scenario is similar to the real-world Dynamic Corridor and is represented in the training dataset.
The robot navigates through a 15×5 m² area with three obstacles placed at uniform intervals in an alternating left-right arrangement. This configuration is NOT in the training dataset.
| Method | Modality | (i) Single SR (%) ↑ |
(ii) Multi (OOD) SR (%) ↑ |
|---|---|---|---|
| NoMaD-FT | RGB | 60 | 10 |
| D-CLING (Ours) | RGB-D | 80 | 100 |
The most dramatic improvement occurs in the out-of-distribution Multi Obstacle scenario (10% → 100%), where RGB-only fine-tuning fails due to delayed avoidance initiation. Depth conditioning strengthens geometric awareness and spatial reasoning, enabling earlier and more robust obstacle avoidance even in unseen obstacle configurations. This validates that our approach successfully transfers learned depth-awareness to novel scenarios.
If you find this work useful, please consider citing our paper.
@inproceedings{nakaoka2026dcling, title = {D-CLING: Prior-Preserving Depth-Conditioned Fine-Tuning for Navigation Foundation Models}, author = {Shintaro Nakaoka and Takayuki Kanai and Kazuhito Tanaka}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2026} }
Notification
The project page was solely developed for and published as part of the publication, titled “D-CLING: Prior-Preserving Depth-Conditioned Fine-Tuning for Navigation Foundation Models” for its visualization. We do not ensure the future maintenance and monitoring of this page. Contents might be updated or deleted without notice regarding the original manuscript update and policy change.
This webpage template was adapted from DiffusionNOCS — we thank Takuya Ikeda for additional support and making their source available.